Bluetoothが使えなくなった(デバイスとして認識されていない)とき
通知領域にアイコンがない、とかそういう状態ではなく、パソコンとしてBluetooth機能を認識していない状態。
対処
- 自分の場合うまくいったのは、完全シャットダウン
- キーボードの
Shiftを押しながら、シャットダウンする。
man(マニュアル)だけ日本語で表示したい
基本は英語表記にしつつ、マニュアルのような分量の多いところだけ日本語で読みたいというわがまま
方法
-Lオプションを使う。
$ man -L ja_JP command
- コマンドによっては日本語訳がないものもあります。
Warning: Key is stored in legacy trusted.gpg keyring(apt-key非推奨)
警告の内容
Ubuntu 22.04から、sudo apt update実行時に下記が表示される(ことがある)。
Key is stored in legacy trusted.gpg keyring (/etc/apt/trusted.gpg), see the DEPRECATION section in apt-key(8) for details.
原因
webminインストール時に公開鍵をkeyring.gpgに登録していたから。
echo "deb http://download.webmin.com/download/repository sarge contrib" | sudo tee /etc/apt/sources.list.d/webmin.list wget http://www.webmin.com/jcameron-key.asc -O - | sudo apt-key add -
修正例(webminの場合)
- keyをダウンロードし、keyringに変換する
$ sudo su $ cd /root $ wget https://download.webmin.com/jcameron-key.asc $ cat jcameron-key.asc | gpg --dearmor >/usr/share/keyrings/jcameron-key.gpg
- 対象のレポジトリと紐付けた形でソースファイルを作成する
- 下記を、
/etc/apt/sources.list.d/webmin.listとして作成 - 1行で書くこと
- 下記を、
deb [signed-by=/usr/share/keyrings/jcameron-key.gpg] https://download.webmin.com/download/repository sarge contrib
誤って登録された公開鍵の削除
keyidを指定して消す
$ sudo apt-key del 11F63C51
keyidは、keyringのリストから確認できるfingerpringの最後の8文字
$ apt-key list
Warning: apt-key is deprecated. Manage keyring files in trusted.gpg.d instead (see apt-key(8)).
/etc/apt/trusted.gpg
--------------------
pub dsa1024 2002-02-28 [SCA]
1719 003A CE3E 5A41 E2DE 70DF D97A 3AE9 11F6 3C51 # ←この最後の8文字
uid [ unknown] Jamie Cameron <jcameron@webmin.com>
sub elg1024 2002-02-28 [E]
Canon LBP3000をUbuntu 22.04で使う
以前、Canon LBP3000をUbuntuで使う、という記事を書きましたが、Ubuntuを22.04(Jammy Jellyfish)にしたら同じ手順を踏んでもプリンターがうんともすんともいわなくなってしまいました。CUPSを見ると、「CCPD: Connection Refused」と出ていますが、所詮は素人なので直し方はわかりません。
ただ、以前にも参照したUbuntu Communityを改めて見てみると、オープンソースのドライバーがあるようなのでそれを使ってみたところ、再び印刷できるようになりました。
なお、私が持っているプリンターはLBP3000ですが、下記シリーズでも問題ないようです。
- LBP2900/LBP2900B
- LBP3000
- LBP3010/LBP3018/LBP3050
- LBP3100/LBP3108/LBP3150
それでは具体的な手順を。
より細かい手順は参考に記載した導入ガイドを参照ください。
必要なライブラリのインストール
$ sudo apt install build-essential automake libcups2-dev $ sudo apt install git
CAPTドライバのインストール
- ダウンロード(git)
$ git clone https://github.com/mounaiban/captdriver.git
- コンパイル
- superuserである必要はない
$ cd captdriver $ aclocal $ autoconf $ automake --add-missing configure.ac:8: installing './compile' configure.ac:6: installing './install-sh' configure.ac:6: installing './missing' src/Makefile.am: installing './depcomp' $ ./configure checking for a BSD-compatible install... /usr/bin/install -c checking whether build environment is sane... yes checking for a race-free mkdir -p... /usr/bin/mkdir -p checking for gawk... no checking for mawk... mawk checking whether make sets $(MAKE)... yes checking whether make supports nested variables... yes checking whether UID '1000' is supported by ustar format... yes checking whether GID '1000' is supported by ustar format... yes checking how to create a ustar tar archive... gnutar checking for gcc... gcc checking whether the C compiler works... yes checking for C compiler default output file name... a.out checking for suffix of executables... checking whether we are cross compiling... no checking for suffix of object files... o checking whether the compiler supports GNU C... yes checking whether gcc accepts -g... yes checking for gcc option to enable C11 features... none needed checking whether gcc understands -c and -o together... yes checking whether make supports the include directive... yes (GNU style) checking dependency style of gcc... gcc3 checking for cups-config... /usr/bin/cups-config checking that generated files are newer than configure... done configure: creating ./config.status config.status: creating Makefile config.status: creating src/Makefile config.status: executing depfiles commands $ make # 中略 $ ppdc -v -d . src/canon-lbp.drv ppdc: Writing ./Canon-LBP3010.ppd. ppdc: Writing ./Canon-LBP2900-3000.ppd.
- インストール
- ここはsuperuserで行う
$ sudo make install $ sudo cp -p /usr/local/bin/rastertocapt $(cups-config --serverbin)/filter/
設定
lpinfoで対象のURIを取得
$ lpinfo -v network lpd network https file cups-brf:/ network beh direct hp network ipps network socket network http network ipp direct usb://Canon/LBP3000?serial=0000A123XYZd # ←これ(シリアルNoはダミー) direct hpfax
- プリンタを登録
- 以前の記事では、自動認識された名前(例えばLBP3000)と同じ名前は不可、と記載したが、今回の手順では、対象のプリンタを削除しておけば問題ないことを確認
$ lpadmin -p LBP3000 -v usb://Canon/LBP3000?serial=0000A123XYZd -P Canon-LBP2900-3000.ppd -E
radikoの録音アプリをGCPのAppEngine上でやっと動かせた話
ラジオを録音したいわけです。自宅PCは電源のオンオフがあるので、できればクラウドサービスを使いたい。
らじる☆らじるに関しては、まあまあうまくいったのですが、radikoが難関でした。
| サービス | らじる☆らじる | radiko |
|---|---|---|
| AWS Lambda | ○ | × |
| AWS EC2 | ○ | ○ |
| GCP Cloud Functions | ○ | × |
| GCP App Engine | ○ | ○(今回) |
| GCP Cloud Run | ○ | × |
| GCP Compute Engine | ○ | ○ |
もっとも、らじるでは15分番組を録るのでLambdaでもよいのですが、radikoではもっと長時間の番組を録る。そう考えたとき、Timeoutまでの時間がネックでした。下表はTimeoutの一覧です。
| サービス | タイムアウト(2022.5現在) |
|---|---|
| AWS Lambda | 15m |
| AWS EC2 | ∞ |
| GCP Cloud Functions | 9m |
| GCP App Engine | 24h(基本スケーリングの場合) |
| GCP Cloud Run | 1h |
| GCP Compute Engine | ∞ |
見て分かる通り、1時間超の番組を録音しようと思ったら、VM以外ではApp Engineしか選択肢がありません。
苦労した点
ローカル環境では問題なく動くスクリプトをApp Engineに載せた途端に動かず、クラウドでのデバッグにも慣れていないため、かなり長い間コーディングのミスを探していました(不毛)。
そんなことで原因が見つかるわけもなく、「radiko側から日本以外からのアクセスとみなされているんだろうな、多分」となかば諦めていたところ、同じ現象の人を発見。
jpdebug.com
東京(ap-northeast1)リージョンで作ったのに、そんなことがあるのかと思い、色々調べていくと、どうやら「GCPが東京リージョンであることと、そのIPがradiko側で東京と認識されることは別物」のようですね。Googleは世界中のIPアドレスを使えるが、各リージョンに対応するIPを振っているわけではない」とか「そのIPの割り振りがダイナミックなので、IPで判定するサイトが持っているデータベースと合わない」とか、私にはどれが完全に正解かはわかりませんでしたが、
GCPが東京リージョンであることと、そのIPがradiko側で東京と認識されることは別物
ということは間違いないなと理解できました。
解決法
サーバレスVPCアクセスを利用します。
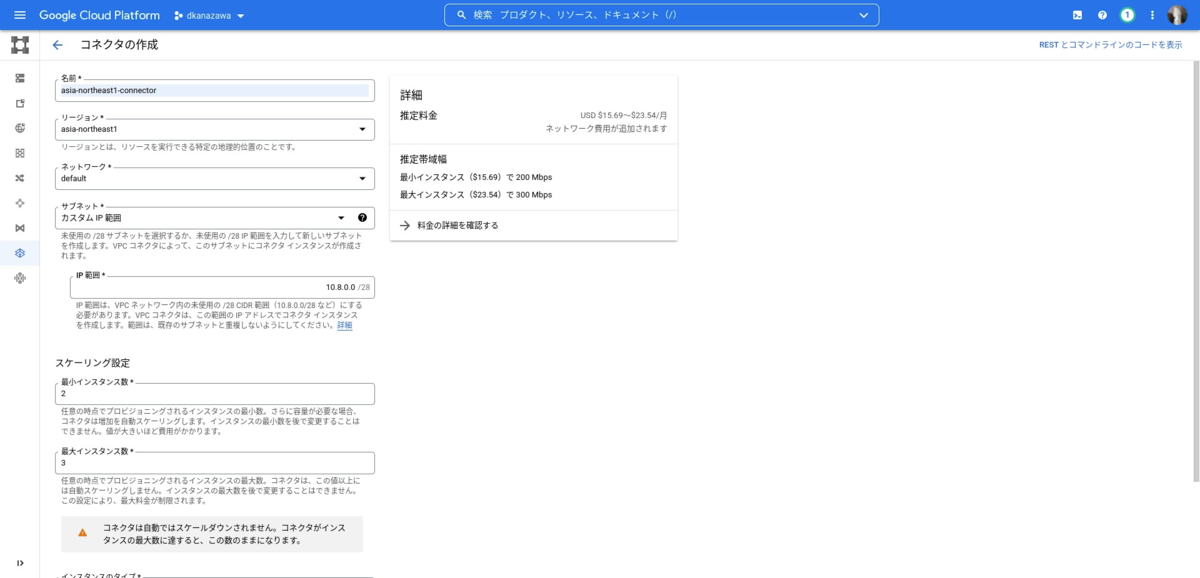
- ハイブリッド接続 > Cloud Routerを作成(Cloud NATの作成時にまとめて作ることも可能)
- ネットワークサービス > Cloud NATを作成
app.yamlにサーバレスVPC設定を追記してデプロイ
# 前略 vpc_access_connector: name: "projects/<** project id **>/locations/<** region **>/connectors/asia-northeast1-connector<** connector name **>" egress_setting: all-traffic # 後略
参考
下記はApp EngineではなくCloud Functionの例ですが、やることはほぼ同じです。
www.isoroot.jp
現実的な課題
VPCアクセスコネクタを作るとき、推定料金が表示されます。
これ何かというと、VPCアクセスコネクタはスペックに応じてCompute Engineと同等のコストがかかるということです。しかも、その最小インスタンスは2以上、最大インスタンスは最小インスタンスより大きい数(つまり最低でも3)を設定しなければいけません。ここが、推定料金にもある通り、$15〜$23のようですから、なるべく低コスト・ノーコストで実装したい身としては重めのコスト負担になってきます。
結局、私個人としては、この”正しい”解決法は諦め、Compute Engineで実装しました。Compute Engineも使うときだけ動かせば、かなりの低コストで済むのです。もちろん、GCEのディスクの使用料は必要ですが、それでもVPCアクセスコネクタ(最低でも e2-micro×2台)ランニングコストに比べればかなり安上がりです。
感想
今回は、結構苦労して解決した割には、お金の都合でボツになってしまって残念でした。
pandas only support SQLAlchemy connectable
現象
いつのバージョンアップからかはよくわからないが、最近pandasの最新版をインストールしたところ、接続情報conにpyodbcのconnectionを使うとタイトルのUserWarningが表示されるようになった。
再現イメージ
import pandas as pd import pyodbc cnxn = pyodbc.connect(*******) pd.read_sql_query(******, cnxn)
原因
原因は警告メッセージに表示される通りで、接続情報conとして認められるのは以下の3種類のみ
1. SQLAlchemyによる接続
1. 接続文字列
1. sqlite3(DBAPI2)
対処(不完全)
SQLAlchemyを使え、というのだから使えばよい。
from sqlalchemy import create_engine cnxn = create_engine('awsathena+rest://{aws_access_key_id}:{aws_secret_access_key}@athena.{region_name}.amazonaws.com/{schema_name}?s3_staging_dir={s3_staging_dir}&...') # 以下同様
問題点
上記の対処法には問題があり、大きな結果データフレームを取得しようとすると時間がかかりすぎてしまうことである。
以下の記事が参考になるが、結果10万行あたりから対処2(後述)と比べて大きな差(2.5秒 vs 21秒)が出てきている。
medium.com
対処2
Boto3を使い、Select結果をS3に保存しダウンロードする、という方法が実用的
具体的な方法は上記の記事の「Method 2: Use Boto3 and download results file」にも詳しいが、ここではAthenaを使う場合のAWS SSOを前提としたコードを備忘として残しておく。
# 以下をまとめて行うpandas.read_sql_query ライクなUDF read_sql_query の作成例 # boto3.client(athena)でs3上に結果を生成 # boto3.client(s3)でダウンロード # pandas.read_csv import subprocess import boto3 subprocess.call("aws sso login --profile your_profile_name") # AWS SSO Login(ブラウザ立ち上がる) boto3.setup_default_session(profile_name = 'your_profile_name') def read_sql_query(queryStr): # クライアントセッションの開始 client_athena = boto3.client('athena') client_s3 = boto3.client('s3') # AWS関係の変数の定義 SCHEMA_NAME = "default" S3_BUCKET_NAME = "query-results" S3_OUTPUT_DIRECTORY = "shipapa15" S3_STAGING_DIR = f"s3://{S3_BUCKET_NAME}/{S3_OUTPUT_DIRECTORY}" temp_file_location: str = "C:/Temp/athena_query_results.csv" query_response = client_athena.start_query_execution( QueryString = queryStr, QueryExecutionContext = {"Database": SCHEMA_NAME}, ResultConfiguration = { "OutputLocation": S3_STAGING_DIR, "EncryptionConfiguration": {"EncryptionOption": "SSE_S3"}, }, ) # クエリの完了まで待機 while True: try: # This function only loads the first 1000 rows client_athena.get_query_results( QueryExecutionId=query_response["QueryExecutionId"] ) break except Exception as err: if "not yet finished" in str(err): time.sleep(1) # import time 要 else: raise err # 結果CSVの取得 client_s3.download_file( S3_BUCKET_NAME, f"{S3_OUTPUT_DIRECTORY}/{query_response['QueryExecutionId']}.csv", temp_file_location, ) return pd.read_csv(temp_file_location)
(Windows10/IME不具合)スペースキーを押しても変換候補が表示されない
現象
タイトルのまま。
Googleの検索ボックスに入力しようとしても、メモ帳で何か書こうとしても、2つ目以降の変換候補が出てこない。
自分は「~~宛」、というのを書こうとして「あて」を変換したのだが「充て」にしかならない。
原因
IMEのバージョンアップが原因のようです。
対処
設定画面から、IMEのバージョンをダウングレードして使えるので、そのように設定する。
1. 設定画面で「IME」と検索し、「日本語 IME 設定」を選ぶ
1. 「全般」を選んで、下にスクロールしていくと「互換性」というセクションがあるので、「以前のバージョンのIMEを使用する」をオンにする。

参考
自分には初めてでしたが、ちょこちょこ不具合の報告があるようです。
vanilla-bear.net
www.japan-secure.com